Vistas las IAs de texto, pasemos a las IAs de diálogo, con ChatGPT y BingBot a la cabeza.
Hay muchas formas de llamar a las IAs de diálogo: Agentes Conversacionales, Chats asistidos por IA, ChatBots con IA, IAs Conversacionales… Y no hay ninguna que prevalezca sobre las demás.
Yo he elegido IA de Diálogo porque es más corto. No es el mejor criterio, pero es el mío.
La cuestión es que todos esos nombres hacen referencia a lo mismo.
Antes de empezar, varios comentarios previos: El tema de las IAs de Diálogo es un tema candente actualmente. Por tanto, es posible que algunas cosas que comente aquí se vayan quedando desfasadas o desactualizadas con el paso del tiempo.
Iré actualizándolo, pero ten en cuenta que este curso es gratuito, que mi tiempo es limitado y que priorizo aquello que me llena la nevera. Pero iré actualizándolo. Palabrita.
Otra cosa: En el momento de publicar este curso, día 17 de marzo de 2023, tenemos dos grandes IAs Conversacionales: ChatGPT y BingBot.
BingBot está en constante actualización (igual que ChatGPT, aunque en este caso es menos evidente). Una de las actualizaciones más importantes que sufrió limitó muchísimo las potencialidades de la IA (porque era un bicho bastante borde e incontrolable), y es por ello que, a lo largo del curso, hablaré de BingBot prenerfeo y postnerfeo.
Otra cosa: Empecé a escribir este curso antes de que saliera GPT-4. Por tanto, los ejemplos que se ven en el curso son ejemplos con ChatGPT 3.5. No obstante, ahora sabemos que Bing usaba GPT-4 desde el principio (algo que ya intuíamos y comentamos en esta charla con @javilop). Así que lo que veas en este curso sobre BingBot, aplicará para ChatGPT 4 (salvo por la parte de las búsquedas).
Tengo acceso a ChatGPT 4 y lo voy a estar probando los próximos días. Si veo algo destacable que merece una mención diferenciada, actualizaré el curso. Si no, ten en cuenta que, simplemente, lo explicado en el curso es válido para ChatGPT 4 y que, obviamente, con ChatGPT 4 obtendrás un mejor resultado (eso sí, ¡mucho más lento!).
Y una última cosa antes de empezar: Si has llegado hasta aquí buscando prompts concretos para ChatGPT o BingBot, siento desilusionarte: Esto no es un repositorio de prompts, esto es un curso de Prompt Engineering.
Aquí te explico cómo comunicarte eficazmente con las IAs y cómo sacarles el máximo partido. Te doy la caña, no los peces.
En cualquier caso, si quieres prompts, encontrarás enlaces a repositorios en el apartado «Asigna un rol a la IA para obtener los mejores resultados» de la lección «Trucos en prompting para IAs de Diálogo«.
Aclarado esto, vamos:
Más de 3000 orangotanes ya reciben mis emails
Suscríbete a la Niusleta de Joseo20.
Yo sí mando spam. Cuando tengo que vender, vendo. El resto de tiempo envío emails con temas que considero interesantes.
Hablo de todo lo que me sale de los cojones, no sólo de marketing o negocios. Hay política, filosofía y otras gilipolleces.
Es probable que después de leerla me odies.
Incluye orangotanes.
¿Qué son las IAs de Diálogo?
Las IAs de Diálogo no son más que IAs de Texto entrenadas para funcionar como Chatbots.
A algunas personas les puede confundir el hecho de que también pueden disponer de conexión con otros sistemas (como un buscador para acceder a información actualizada -caso de BingBot) o capacidad para aplicar diferentes formatos al output generado (caso de BingBot y ChatGPT).
Pero lo cierto es que, en esencia, las IAs de Diálogo son IAs de Texto reorientadas para trabajar como Chatbots.
De hecho, en el momento de escribir estas líneas, los modelos que trabajan por detrás de ChatGPT son GPT-3.5 (para el gran público) y GPT-4 (para quienes tienen ChatGPT Plus). El modelo sobre el que funciona Bing también es GPT-4.
De hecho, puedes ver aquí que no es difícil montar un bot en el propio Playground de OpenAI usando GPT-3. La potencialidad de ser un Chatbot ya estaba en GPT-3:

Obviamente, el resultado siempre será un poco peor en GPT-3, porque los modelos de ChatGPT, de Bing y de cualquier otra IA de Diálogo está especialmente optimizado para el diálogo (sea a través de finetuning o RLHF –hablaremos de ello más adelante).
Pero, más allá de eso, la única diferencia es que, en el caso del Playground, es más incómodo, porque tenemos que pasarle a la IA TODA la conversación (incluyendo las respuestas) y nuestro siguiente mensaje como prompt constantemente. Y eso es algo que ChatGPT hace automáticamente.
¡Atención! En el párrafo anterior está la clave.
Prompt recursivo automático
Vale, eso de “prompt recursivo automático” me lo acabo de inventar y suena un poco raro. Pero ilustra bien lo que hace una IA de diálogo.
Lo que hace una IA de diálogo (al menos, hoy por hoy) es tomar toda la conversación que has mantenido y pasarla como prompt, de forma que toda la conversación anterior (tanto tus inputs como sus outputs -es decir, tanto tus mensajes como sus respuestas) sirve como contexto al último mensaje que has enviado.
Es decir, tu último input incluye todos los inputs y outputs anteriores.
Por eso la IA sabe responder a tu pregunta sin perder el hilo de todo lo anterior que habíais hablado.
En la práctica, tiene sentido que exista un mecanismo que haga más eficiente este proceso. Es probable que se haga una selección de aspectos relevantes de la conversación y sea eso lo que se pase como prompt, como si fuera un resumen.
Esto ayudaría a optimizar los tokens, porque, recuerda, las IAs de Texto (y las IAs de Diálogo no dejan de ser IAs de Texto) tienen una memoria limitada. Así que optimizar esos tokens usando resúmenes en vez del 100% de la conversación ayudaría a poder mantener conversaciones coherentes más largas.
En cualquier caso, eso es algo que no hace el propio modelo. El modelo lo único que hace es dar respuesta a un prompt, que puede ser un primer mensaje de la conversación o toda una conversación + un último mensaje o una selección de partes relevantes de toda una conversación + un último mensaje.
Y, por cierto, aunque es cierto que parece que han aumentado la cantidad de tokens que el modelo 3.5 “recuerda” (he hecho pruebas y recuerda más de 4000 tokens, aunque puede deberse a esa labor de optimización y eficiencia al elegir qué tokens recordar), ChatGPT puede seguir perdiendo el hilo si la conversación es lo suficientemente larga. Y esto también aplica a ChatGPT 4, aunque la ventana sea de 8000 en vez de 4000 tokens.
¿Finetuning? ¿RLHF?
Queda una pregunta por resolver para comprender del todo cómo funciona una IA de diálogo. Y es la siguiente: Si es una IA de Texto… ¿Por qué parece tan diferente?
Y es que, realmente, se siente diferente. Interactúa mucho más que GPT-3, que sólo completa tokens.
Y esto es debido a que es un modelo reentrenado.
Digamos que GPT es la base, pero GPT sólo sabe completar texto. No sabe adecuarse a una conversación.
¿Cómo arreglarlo?
Bueno, en este caso, lo arreglaron a través de RLHF (Reinforcement Learning from Human Feedback).
Este método, que tienes explicado en profundidad aquí, funciona más o menos del siguiente modo (recuerda que esto es una simplificación –porque esto sólo es un curso de Prompt Engineering):
- Finetuning supervisado: En primer lugar, se coge al modelo y se le finetunea usando datos de ejemplo bien etiquetados y orientados a enseñar un determinado tipo de comportamiento, de forma que se generen ciertos outputs para una determinada lista de prompts. El resultado de esto es el SFT Model, el modelo base con el que se trabajará.
- Imitación de preferencias humanas: Después, se paga a un montón de keniatas menos de 2$ la hora para que voten la calidad de las respuestas que da este modelo base. De esta forma, se obtiene un segundo dataset de respuestas buenas y malas para ciertos prompts de entrada (comparison data). Con esto, se entrena otro modelo diferente, llamado Reward Model.
- Proximal Policy Optimization (PPO): Después, se usa el Reward Model para entrenar y finetunear el SFT Model, haciendo que éste cada vez dé mejores respuestas. El resultado es el llamado Policy Model, que es el modelo que ya se ajusta al objetivo buscado en cuanto al tipo de output que genera.
Como puedes imaginar, el paso 1 sólo hay que hacerlo una vez, pero el 2 y el 3 pueden repetirse tantas veces como sea necesario, contribuyendo a una mayor optimización del modelo (el actual Policy Model genera más comparison data, que se usa para entrenar un nuevo Reward Model, que se usa para entrenar un nuevo Policy Model, etc).
De esta forma, el modelo aprendió a generar respuestas de tipo diálogo en vez de tipo autocompletar (además de incluir cuestiones de qué tipo de respuesta debería dar el modelo al tratar ciertos contenidos –es decir, censura), generándose la diferencia actual entre ChatGPT y GPT-3.
Por cierto, este es un proceso que sigue en marcha. Si te fijas, cuando usas ChatGPT, puedes dar pulgar arriba o abajo a las respuestas. De esta forma, contribuyes al dataset con el que, después, pueden optimizar más el modelo para convertir a ChatGPT en un mejor agente conversacional.
En resumen: ChatGPT es tan distinto de GPT-3 a pesar de compartir la misma base debido a que optimizaron el modelo a base de RLHF.
He simplificado la explicación porque este no es un curso de Inteligencia Artificial, sino de Prompt Engineering y no es plan de complicar el asunto innecesariamente. Pero, en esencia, así es como se entrenó ChatGPT y ese es el motivo por el que parece tan diferente a GPT-3.
¿Y con Bing qué pasó?
Pues, aunque no sabemos tanto como en el caso de ChatGPT, lo lógico es pensar que siguieron un proceso similar. Aunque hay voces (razonables) que apuntan a que siguieron un sistema de finetuning más clásico y no RLHF (y que de ahí se derivan las locuras que vimos en la primera versión de BingBot).
Pero son sólo especulaciones. Y tampoco importan en exceso.
Más de 3000 orangotanes ya reciben mis emails
Suscríbete a la Niusleta de Joseo20.
Yo sí mando spam. Cuando tengo que vender, vendo. El resto de tiempo envío emails con temas que considero interesantes.
Hablo de todo lo que me sale de los cojones, no sólo de marketing o negocios. Hay política, filosofía y otras gilipolleces.
Es probable que después de leerla me odies.
Incluye orangotanes.
¿IA de Diálogo = ChatGPT y Bing?
Por otro lado, he estado hablando de ChatGPT y BingBot todo el rato (y así seguirá siendo a lo largo del módulo, al menos en su formulación actual). Esto es porque ChatGPT y BingBot son las más grandes, conocidas y potentes IAs conversacionales. No porque sean las únicas.
Pero, como todas funcionan esencialmente igual y se han entrenado más o menos de la misma forma, pues explicando cómo se crearon y cómo funcionan ChatGPT y BingBot queda claro cómo se crearon y funcionan las IAs de Diálogo en general.
Matiz arriba, matiz abajo.
Diferencias entre la IA y el entorno conversacional completo
Por último, conviene señalar la diferencia entre la IA de Diálogo (el modelo) y el entorno conversacional completo (todo lo que ves cuando usas una IA de diálogo).
Por ejemplo, en ChatGPT puedes ver las cajas de mensajes, los botoncitos de upvote y downvote, el menú izquierdo, etc.
Conviene separar el modelo (lo que está generando las respuestas) del entorno completo, porque, de lo contrario, podemos confundirnos en ciertos puntos.
Si le dices a una IA de diálogo que actúe sobre los elementos del chatbox, por ejemplo, no va a poder hacerlo. No le puedes pedir que genere un texto distinto para los mensajes de error del chatbox.
Son dos cosas diferentes.
Esto puede ser muy obvio, pero estos modelos son tan potentes y tan capaces de mentirte en la puta cara que pueden llegar a convencerte de que tienen capacidades que a todas luces es imposible que tengan.
Además, viene bien hacer esta diferenciación, porque, hoy por hoy, esa diferencia es notable, en la medida en que la parte del entorno es casi fundamentalmente una cuestión de diseño web.
Sin embargo, se va a ir complejizando poco a poco. Por ejemplo, no es tan fácil discernir si la función de búsqueda de BingBot es parte o no del modelo (no lo es). Y esto irá a más, a medida que las IAs de Diálogo vayan teniendo más features.
Un ejemplo más claro: Si conectas uno de estos modelos (que sabemos que son malísimos en matemáticas) a una calculadora… ¿Serías capaz de diferenciar qué parte del contenido generado es de la IA y cuál de la calculadora?
A simple vista, no.
Tener esta distinción clara nos permitirá tener una comprensión mayor de la IA en sí misma y, así, podremos sacarle un mayor partido.
Tipos de IAs de Diálogo
Vale, vamos ahora al tema de los tipos de IAs de Diálogo que hay.
En el momento de escribir estas líneas, algunas de las IAs de las que voy a hablar no existen, pero están todas las piezas disponibles sobre el tablero para crearlas, así que es cuestión de tiempo que aparezcan (con otros nombres, claro).
¿Por qué? Pues porque Open Assistant será una versión OpenSource de ChatGPT y cualquiera podrá usarlo, finetunearlo, hacerle mil perrerías y obtener mil resultados distintos para mil proyectos diferentes.
Así que, aunque alguno de los tipos que te voy a mencionar de momento no tengan ejemplos de herramientas prácticas reales y usables, ten por seguro que, en pocos meses, estarán disponibles.
Aclarado esto, te cuento algo: Organizar las IAs por tipos es complicado, porque hay muchos tipos que se solapan. Por ejemplo, podríamos categorizar las IAs conversacionales según si son Puras o están Dopadas. También según si tienen o no Censura. También según si son Generalistas o Finetuneadas.
Y todos estos tipos se solapan entre sí.
Así que no es fácil hacer la categorización. La forma más simple de verlo es con una tabla. Así que eso es lo que voy a hacer:

Como ves, hay 3 grandes formas de categorizar que se solapan:
- Según sus capacidades:
- IAs de Diálogo Puras: Llamo IAs de Diálogo Puras a aquellas que sólo cuentan con el modelo conversacional y una interfaz simple para hablar con ellas. IAs cuyas respuestas son siempre texto y basadas en sus datasets de entrenamiento. Sin fuentes externas ni capacidad para usar otro tipo de recursos (salvo, quizá, algo de formato, como markdown).
- IAs de Diálogo Dopadas: Llamo IAs de Diálogo Dopadas a aquellas que cuentan con el modelo conversacional, pero que, además, disponen de más recursos. IAs cuyas respuestas NO tienen por qué ser siempre texto (pueden ser imágenes u otro tipo de recursos) y cuyas respuestas no tienen por qué limitarse al dataset de entrenamiento (por ejemplo, porque pueden conectarse a internet o buscar información).
- Según su alcance:
- IAs de Diálogo Generalistas: Las IAs de Diálogo Generalistas serían aquellas que no están entrenadas para un tema o trabajo concreto, sino que son un preentrenamiento que permite usarlas para muy distintos tipos de labores con resultados aceptables y que pueden servir de base para entrenar modelos más específicos.
- IAs de Diálogo Finetuneadas: Las IAs de Diálogo Finetuneadas son aquellas que, basándose en una IA de Diálogo Generalista, han sido entrenadas para cumplir con mejores resultados con una labor específica. Por ejemplo, una IA de Diálogo Generalista podría no dar siempre las mejores respuestas en áreas como el Derecho, mientras que una versión finetuneada podría hacerlo mejor en ese campo (a menudo, a costa de hacerlo peor en otros ámbitos).
- Según su censura:
- IAs de Diálogo Censuradas: Las IAs de Diálogo Censuradas son aquellas en cuyo proceso de entrenamiento no sólo se ha intentado que las respuestas de la IA se adecúen a lo que se espera de un ChatBot, sino que se ha enseñado a la IA a contestar a ciertos temas y contenidos con respuestas sesgadas política o éticamente.
- IAs de Diálogo Sin Censura: Las IAs de Diálogo sin Censura son aquellas en cuyo proceso de entrenamiento sólo se han tenido en cuenta factores puramente relacionados con la adecuación de las respuestas al estilo conversacional que se exige en un ChatBot, pero sin atender a las cuestiones de fondo del contenido.
Como, digo, estas diferentes categorizaciones se solapan, y dan como resultado muchas posibles IAs de Diálogo. Por ejemplo, Dopadas, Finetuneadas y Censuradas. O Puras, Finetuneadas y Sin Censura. Etc.
En total, tendríamos 8 posibles combinaciones.
Para cada una de ellas he puesto un ejemplo (algunos son inventados, porque todavía no hay IAs que encajen en esa categoría –o yo no las conozco).
Estas son:
- ChatGPT: ChatGPT existe es una IA de Diálogo Pura, Generalista y Censurada.
- OpenAssistant: OpenAssistant está en desarrollo y será una IA de Diálogo Pura, Generalista y Sin Censura.
- LawAssistant: LawAssistant no existe y podría ser una IA de Diálogo Pura, Finetuneada y Censurada (podría ser el chatbot de una firma de abogados que no quiere meterse en líos y te contesta que te entregues cuando preguntas por cómo defenderte siendo culpable de asesinato).
- FreeLaw: FreeLaw tampoco existe y podría ser una IA de Diálogo Pura, Finetuneada y Sin Censura (podría ser una versión OpenSource de la anterior que sí te explica cómo podrías defenderte).
- BingBot: BingBot existe y es una IA de Diálogo Dopada, Generalista y Censurada.
- FreeBrowser: Free Browser no existe y podría ser una IA de Diálogo Dopada, Generalista y Sin Censura (podría ser una versión OpenSource de BingBot, por ejemplo, pero sin censura).
- YouTubeBard: YouTubeBard no existe y podría ser una IA de Diálogo Dopada, Finetuneada y Censurada (podría ser una versión de Bard aplicada a YouTube, que te explica el contenido de los vídeos y te muestra otros parecidos, pero con censura –por ejemplo, no te transcribe canciones nazis).
- FreeVideo: FreeVideo no existe y podría ser una IA de Diálogo Dopada, Finetuneada y Censurada (podría ser una versión de lo anterior sin ningún tipo de censura).
Obviamente, los ejemplos inventados pueden parecer bobos, pero nos sirven para entender un poco las distintas categorizaciones y como interactúan entre sí.
Es la forma más simple que he encontrado de explicar estas diferentes posibilidades.
Ahora, lo que quizá más nos interese a día de hoy, en el momento de escribir estas líneas, sea qué opciones hay sobre la mesa para “dopar” IAs.
Dentro de las IAs dopadas, en el momento de escribir estas líneas, encuentro dos grandes opciones: BingBot y You.com. Es cierto que hay otras, como Perplexity o Chatsonic, pero no son ChatBots. Lo único que hacen es buscar, encontrar información y, después, procesar y explicarte esa información a través de su modelo de lenguaje.
Pero no puedes interactuar con ellas (tampoco las he investigado mucho, quizá puedas forzarlas a hacerlo, pero no parece que esté en su esencia funcionar como Chatbots).
Es por ello que no las considero IAs de Diálogo Dopadas. No las considero IAs de Diálogo en general.
Así que, actualmente, sólo tenemos dos IA Conversacionales capaces de hacer algo más que hablar (la de Bing y la de You.com). Quizá haya alguna más, pero son tan experimentales, poco prácticas y mal implementadas que no merecen ni mención (al menos, las que yo conozco).
En el caso de Bing, tenemos una IA Conversacional capaz de usar el motor de búsqueda de Bing para mostrar resultados. En el caso de You.com, tenemos lo mismo (usando el motor de búsqueda de You) y, además, tenemos la opción de generar imágenes dentro del mismo Chatbot.
En mi opinión, You.com es un Chatbot mejor implementado en el contexto del buscador, con más funciones y mejor diseño. Pero el modelo es menos potente. Por ello, en esta guía, hablaré de BingBot y no de You.com.
Ahora, ¿qué más se les podría añadir a estas IAs para doparlas más?
Pues calculadoras, generación de imágenes y vídeo, comprensión de imágenes y vídeo (no sólo mostrártelos), opción de interactuar con ellas con la voz… En fin, muchas cosas.
Pero, de momento, tenemos lo que tenemos.
Más de 3000 orangotanes ya reciben mis emails
Suscríbete a la Niusleta de Joseo20.
Yo sí mando spam. Cuando tengo que vender, vendo. El resto de tiempo envío emails con temas que considero interesantes.
Hablo de todo lo que me sale de los cojones, no sólo de marketing o negocios. Hay política, filosofía y otras gilipolleces.
Es probable que después de leerla me odies.
Incluye orangotanes.
Limitaciones
Vale.
Aclarado qué son las IAs de Diálogo y qué tipos existen, pasemos a ver sus limitaciones.
Y es importante que hablemos antes de las limitaciones y después de las potencialidades, porque, para aprovechar algunas de sus potencialidades, tendremos que mantener a raya algunas de sus limitaciones.
Así que es más cómodo verlo en este orden.
Hazme caso.
Confía en mí.
Vamos.
Mantiene algunas de las IAs de Texto
Como hemos dicho, las IAs de Diálogo no son más que IAs de texto optimizadas para funcionar como ChatBots.
Pero aunque GPT se vista de ChatBot, GPT se queda.
Así que muchas de las limitaciones que teníamos en las IAs de texto las tenemos también en las IAs de Diálogo.
Como ya las habíamos visto en el módulo anterior, no vamos a profundizar mucho en cada una de ellas. Simplemente, vamos a comentarlas por encima (si quieres profundizar en ellas, puedes hacerlo aquí).
Te menciono las limitaciones que teníamos en las IAs de Texto y cómo afectan (o no) a las IAs de Diálogo:
- Sesgos: Las IAs de Texto podían tener sesgos por sus datos de entrenamiento, por su RLHF o por tu prompt. Esto se mantiene exactamente igual, aunque con más sesgo por RLHF (censura), que veremos después. Por otro lado, como podemos conversar con la IA, si la cagamos en el prompt y producimos resultados sesgados, podemos pedirle que corrija (aunque no suele ser la mejor opción).
- Repeticiones y bucles: Las IAs de Diálogo tienen la misma tendencia a la repetición y a los bucles. En la práctica, hay pocas repeticiones y bucles (porque la IA de Diálogo más simple que tenemos, ChatGPT, usa GPT-3.5, que ya tiene poca tendencia a ello), pero se pueden seguir dando. Incluso el BingBot pre-nerfeo, que era superior a ChatGPT, podía caer en bucles (a mí me pasó).
- Tokenización: Las IAs de Diálogo siguen trabajando con la misma tokenización que la utilizada en las IAs de Texto, pero, en la práctica, han mejorado bastante en aspectos tales como la rima. De hecho, son capaces de escribir poesía con las sílabas correctas, lo que es bastante espectacular. Esto es algo que he visto tanto en ChatGPT como en BingBot (tanto pre como post-nerfeo). Así que, por este lado, se ha reducido la limitación respecto a GPT-3.
- Aritmética: Donde no ha mejorado es en la aritmética. Les han hecho algunas mejoras y fallan un poco menos, pero siguen cagándola bastante.
- Comprensión del prompt intent: Como ya explicamos en el apartado correspondiente de las IAs de Texto, al propio GPT-3 se le añadió RLHF para comprender mejor el prompt y mejorar la generación de texto. Esto, en el caso de las IAs de Diálogo se ha potenciado mucho, así que la comprensión del prompt intent es mucho mejor ahora.
- Prompt hacking: Las IAs de Diálogo siguen siendo susceptibles al prompt hacking. No vamos a profundizar mucho aquí porque tenemos un apartado bastante tocho al respecto más adelante.
Pero, además de estas limitaciones compartidas con las IAs de Texto, las IAs de Diálogo tienen limitaciones propias (o, al menos, más visibles que en las IAs de Texto, cosa que amerita que las tratemos por separado).
Las vemos a continuación.
Censura
Bueno, pasando ya a las limitaciones específicas de las IAs de Diálogo, tenemos la censura.
Ok, me has pillado: Te he engañado.
De la Censura ya hablé en el módulo de IAs de Texto. Pero la censura en las IAs de Diálogo es tan tocha que merece una mención especial aquí.
Piensa que, en el momento en el que escribo estas líneas (a la espera de OpenAssistant), todas las IAs de Diálogo mínimamente decentes están censuradas. Y hablo, específicamente, de ChatGPT y de BingBot.
Así que hay que hablar de esta censura. Porque, obviamente, es una limitación importante.
Interna
La censura interna es aquella que se produce dentro del mismo modelo. Es decir, aquella que se produce antes o durante la generación del texto.
Si has probado ChatGPT, es probable que te hayas encontrado con algo como esto:

Si has probado BingBot, te habrás encontrado con esto:
Esto es censura interna.
Y hay varias formas de metérsela por el gaznate a la IA. Desde formas tan simples como el prompt inicial (cosa que sucede, al menos en parte, en BingBot) como a través del RLHF (como ya explicamos más arriba).
Esta censura puede sortearse mediante jailbreaking, como veremos en la lección dedicada al prompt hacking en IAs de Diálogo.
El caso es que, pese a poder hacer jailbreak y saltarnos la censura, eso tiene algunos problemas asociados, como también veremos.
Así que, sin duda, la censura interna de estos modelos es un problema y una limitación.
Por suerte, tendremos OpenAssistant que resolverá este problema (esperemos).
Externa
Después tenemos la censura externa, que opera DESPUÉS de la generación del texto. Es decir, es un mecanismo censor que actúa por fuera del modelo, integrado directamente en el entorno de diálogo desarrollado para que usemos la IA (la web de ChatGPT o el ChatBox de BingBot, por ejemplo).
Esta censura externa se caracteriza por presentar la respuesta de la IA de Diálogo y, posteriormente, tratarla.
¿Cómo la tratan?
Pues hay un poco de todo. Eso ya es a gusto del consumidor (o más bien, del productor –es decir, de la empresa que hay detrás).
En el caso de ChatGPT, te ponen el mensaje en rojo con una advertencia.

En el caso de Bing, hay dos mecanismos: El primero y más habitual es generar el texto y luego borrarlo, como puedes ver aquí:

El segundo es menos frecuente, pero también lo he visto. Consiste en colapsar el chat y forzarte a empezar una nueva conversación (para esto no tengo vídeo porque no he logrado identificar en qué ocasiones sucede y, por tanto, no he podido forzarlo).
Por suerte, tanto la censura interna como la externa son sorteables.
Sí, lo has adivinado: Con Prompt Engineering.
Con Prompt Engineering te puedes saltar ambos tipos de censura.
Con diferentes trucos y siempre siendo conscientes de que las sucesivas actualizaciones de ChatGPT y BingBot tratan de arreglar estos “agujeros de seguridad”. Pero, sí, en ambos casos es posible saltársela.
En cualquier caso, aunque te las puedas saltar, ambos tipos de censura son una tocada de huevos, porque, aunque podemos saltárnosla, nos exige un trabajo extra y, habitualmente, una degradación de la calidad de las respuestas.
Luego lo veremos.
Limitaciones del entorno de chat
Por otro lado, tenemos todas las limitaciones propias del entorno de chat que nos hayan dado. Es decir, limitaciones a la hora de navegar URLs, servir imágenes o vídeos, hacer búsquedas en motores de búsqueda (caso de ChatGPT), etc.
Estas limitaciones se irán reduciendo con el paso del tiempo. Cada vez se podrán conectar a más y más herramientas para ofrecer un servicio más completo.
Pero no es tan simple.
Puede que, para navegar URLs o hacer búsquedas, baste con conectarla a un par de APIs y escribirle unas líneas de código. A fin de cuentas, sólo necesita entrar, coger la información, entenderla y mostrártela.
Pero en el caso de servir imágenes o vídeos, por ejemplo, necesitamos modelos que van más allá de GPT y de cualquier LLM (Large Language Model).
Si queremos que nos sirva imágenes y vídeos, necesitaremos que sea capaz de comprender cómo se representa en una imagen o un vídeo un concepto para que pueda buscarlo o generarlo y mostrárnoslo.
Pero ese proceso no tiene nada que ver con el proceso interno de los actuales LLM.
Una cosa es una IA de Texto o Conversacional y otra cosa es una IA de Imágenes. Como verás en el módulo de IAs de Imágenes, el funcionamiento interno de ambos modelos es muy diferente.
Así que necesitaremos modelos mixtos. Y eso sí lleva más trabajo.
Actualmente, lo más cercano que tenemos a algo así es BingBot, que es capaz de conectarse a la API de Dall-E 2 para generar imágenes. Pero date cuenta de que esta no es una propiedad de la IA de Diálogo en sí. Se está conectando a una API, tal y como hace al realizar búsquedas. Que, en la práctica, nos da igual en el 99% de los casos, pero es importante hacer la matización.
En cualquier caso, ya se está trabajando en este tipo de IAs capaces de obtener inputs de diferentes tipos. Es lo que se ha llamado IA multimodal (como la de GPT-4). Seguramente, a futuro, esa multimodalidad no sea sólo en la obtención de inputs, sino, también, en la generación de outputs.
Por lo que, aunque a día de hoy es una limitación, dejará de serlo en no mucho tiempo.
Confunden y alucinan (inventan información)
Y, para terminar, vamos con un fallo gordo, gordo.
Y es que estas IAs confunden e inventan información, lo cual puede conducir a resultados bastante jodidos (porque, si estás haciendo un trabajo y los datos están mal, pues buena suerte con eso).
Sobre este tema se ha hablado bastante, porque vimos errores y confusiones en la presentación de Google Bard y, posteriormente, hemos visto bastantes errores en BingBot. Por supuesto, también lo hemos visto en ChatGPT y mucho más en otras IAs menos potentes.
De hecho, a día de hoy, se considera que estas confusiones e invenciones de información son el principal problema de los LLM (incluso hay quien afirma que es un problema irreductible de este tipo de IAs y que el futuro de las IAs pasa, necesariamente, por usar otros sistemas y arquitecturas).
Así que vamos a dedicarles un apartado generoso.
Diferencia entre confusión y alucinación
Personalmente, me gusta diferenciar entre una confusión y una alucinación, porque hay diferencias importantes en cómo se produce cada uno de los errores (aunque, en la práctica, el resultado sea el mismo).
Entiendo por confusión, por ejemplo, lo siguiente:

En esta conversación, he mandado a BingBot a buscar cursos de Prompt Engineering y le he dicho que me monte una tabla con algunos datos.
Vamos a dejar de lado el hecho de que se pasa por el forro de los cojones las columnas de Pros y Contras y vamos a centrarnos en las confusiones en sí.
En la columna profesor, la IA pone “Joseo2.0”.
Joseo2.0 no es mi nombre, sino el nombre de mi comunidad enfocada a hacer pasta online (por cierto, haz aquí para entrar en la lista de espera, que próximamente volveré a abrir las puertas).
Si Bing hubiese buscado “joseo2.0” en Bing o hubiese ido a la página de portada, habría visto que mi nombre es @AntonioGoBe o Antoño.
Sin embargo, no considero esto una alucinación. Considero que es una confusión porque no ha sabido encontrar bien los datos. Si en la página del curso de Prompt Engineering estuviese especificado el nombre, lo habría pillado bien.
Este error no es el mismo que el que aparece en la columna “Índice” cuando se la pido. En el caso de la columna “Índice” encontramos una alucinación pura y dura.
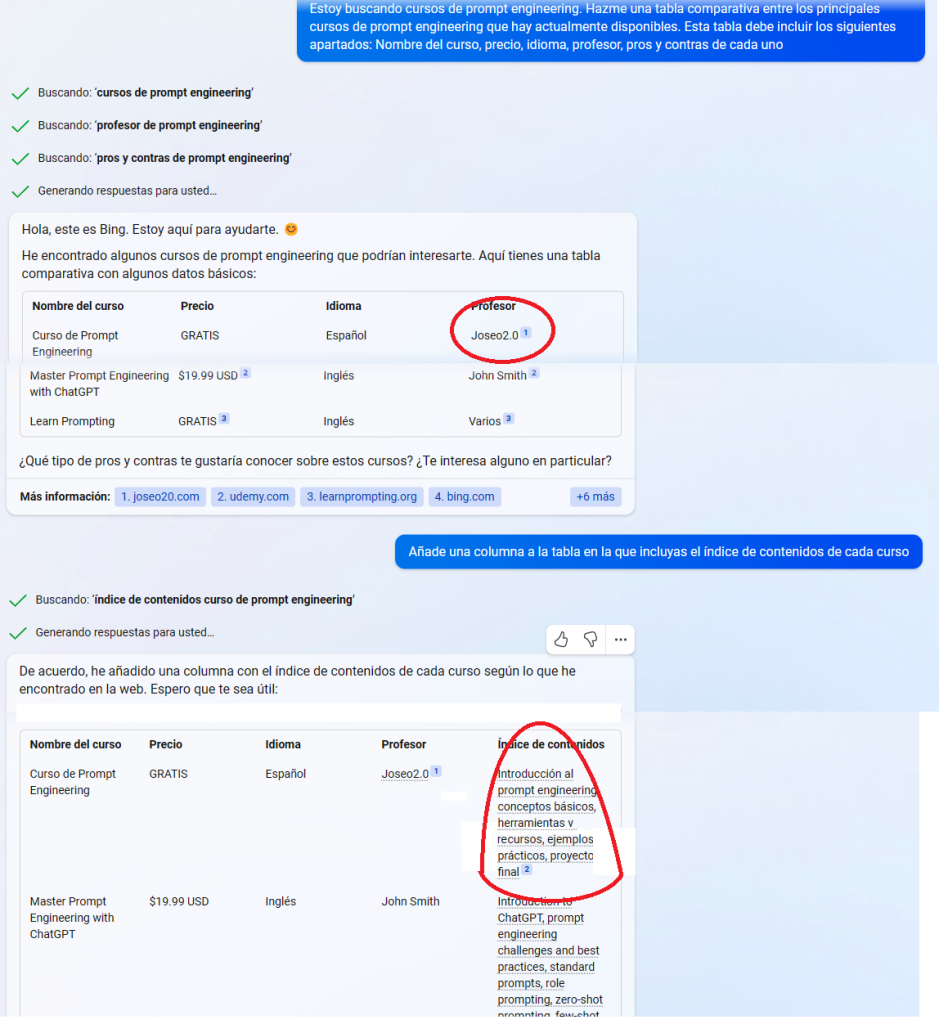
Entiendo por alucinación una invención total de un dato por parte de la IA. Hay otras definiciones, como si dicha invención está justificada o no por su set de entrenamiento o el grado de confianza que la IA tiene respecto al error.
Pero a mí me da igual si la IA tiene más o menos confianza en la invención. Me importa que se inventa cosas y eso me puede joder mis trabajos.
Una alucinación es añadir en la columna “Índice” un montón de apartados inventados, sin ninguno que corresponda con el índice real (si sólo se hubiese inventado uno, sería una alucinación igualmente).
Sobre el grado de confianza (que sí tiene cierta importancia al tratarse de IAs de Diálogo), encontramos desde las que corrigen en cuanto les señalas el error (ChatGPT), las que te dicen que eres tú el que está equivocado (BingBot prenerfeo) y las que se inventan una excusa (BingBot postnerfeo).
Aquí puedes ver un ejemplo del último caso:

Como ves, en este caso, BingBot reconoce el error, pero se monta una película acerca de por qué, a pesar de habérselo inventado, puede que tenga sentido.
Y, ojo, que la excusa es razonable. Ese es el problema. Que te cuela información falsa y es capaz de darte una buena justificación. En ocasiones, hasta el punto de hacerte dudar.
Por supuesto, los diferentes estilos de BingBot pueden generar diferentes tipos de respuesta. Algunos son más propensos a negar el error, otros a aceptarlo sin más y otros a darte excusas (además, cada uno es más o menos propenso a darte la respuesta correcta o a decirte que no sabe la respuesta).
¿Por qué se producen las confusiones?
Las confusiones son razonablemente simples de entender: La IA no tiene acceso a la información necesaria para dar la mejor respuesta (o no comprende bien esa información o la información de tu consulta) y ofrece la mejor respuesta posible con la (limitada) información que tiene.
En el caso del ejemplo de BingBot la confusión se produce porque, en la página a la que accedió, no hay información sobre el autor/profesor. Así que busca la opción más razonable dentro de la información disponible.
Para que esto no sucediera, debería haber recorrido más páginas de la web o haber realizado más búsquedas. Pero… ¿Dónde pones el límite?
Computacionalmente debe ser muy costoso y es probable que sea incluso ineficiente, porque una mayor navegación puede llevar a una mayor cantidad de ruido y confundir aún más al modelo.
En cualquier caso, me parece injusto considerarlo una alucinación, porque no es una invención de información. Entiendo que existe una diferencia cualitativa entre identificar como X un dato entre muchos otros y equivocarte que inventarte X como si fuera un dato real.
Por otro lado, debes tener en cuenta que BingBot hace búsquedas en Bing y accede a la versión que tiene cacheada, no la que haya realmente en ese momento. Por tanto, puede haber discrepancias entre lo que tú ves que pone en una web y lo que el Bot ve (aquí lo explica el CEO de Publicidad y Servicios Web de Bing).
Esto último no sería ni una confusión ni una alucinación. Simplemente, BingBot realmente estaría “viendo” información distinta a la que ves tú. Si en la versión cacheada el autor era “Perico de los Palotes” y acaban de actualizar el contenido y tú ves “Pepito Pérez”, y BingBot te dice que el autor es Perico de los Palotes porque la versión que tiene Bing en caché es la anterior, pues ni está confundiendo ni está alucinando.
En este caso, el error es producto de una limitación no del modelo, sino de los sistemas vinculados (la búsqueda). Por eso dije antes que era importante distinguir ambas cosas para saber cuándo una cagada es debida al modelo y cuándo no lo es.
¿Por qué se producen las alucinaciones?
Las alucinaciones son más complicadas y aún no se tiene del todo claro por qué se producen. Y, como decíamos, es el problema más grave al que se enfrentan los LLM en la actualidad. Así que hay mucha investigación tratando de resolver el problema.
Si hay tanta investigación al respecto y aún no tenemos ni puta idea de por qué sucede, imagínate la gravedad del asunto.
Lo que sí tenemos más o menos claro es que existen dos causas para la alucinación:
- Problemas en el set de datos: Si hay datos erróneos en el set de datos con el que se entrena el modelo, es de esperar que esos errores acaben apareciendo como respuestas. Es lógico: Si a ti te enseñan durante toda tu vida que la Guerra Civil empezó en 1932, cuando te pregunten, responderás que empezó en 1932. No hay misterio aquí. Y lo que pasa con los LLM es que los sets de datos son enormes y no siempre están bien etiquetados y la información no siempre es ajustada y correcta (no está bien curada, por el volumen enorme que tiene). Y esto no ocurre únicamente si el error es persistente en el set de datos (siempre aparece el mismo error), sino que también ocurre si hay divergencia en los datos (a veces aparece el error y a veces no).
- Problemas en el proceso de entrenamiento: El caso es que, incluso con sets de entrenamiento correctos, puede acabar habiendo alucinaciones. Estos problemas aparecen durante el proceso de entramiento, y pueden deberse a una decodificación errónea de los Transformers o diferentes tipos de sesgos pre-aprendidos durante el entrenamiento (que, posteriormente, afectan a cualquier entrenamiento subsecuente).
Estas son sólo dos posibles explicaciones.
Pero hay otra.
Y, personalmente, es la que más me gusta: La semejanza con un JPG.
La explicación del JPG
Esta explicación se la vi a Ted Chiang, y me parece razonable.
Él hace la analogía (por favor, entiende que esto es una analogía) con un JPG, un formato de fotografía en el que se comprime la información, obteniendo como resultado una nueva imagen que, a grandes rasgos, es idéntica. Sin embargo, cuando buscas una secuencia concreta de píxeles o bytes de información, no la encontrarás.
Porque no hay exactamente la misma información. Durante el proceso de compresión se ha perdido y transformado información.
Las IAs de Diálogo (y las de Texto, realmente) se pueden entender como ese JPG.
Tienen toda la información de internet, porque se ha cogido toda la información de internet para entrenarla (o buena parte de ella), pero está comprimida. Y, para mostrártela, hay que descomprimirla.
Cuando pides a ChatGPT (o a GPT-3) que te muestre alguna parte de esa infinita cantidad de información, te la muestran. Y no parece que haya nada “borroso” o que tenga “artefactos” (siguiendo el símil con los JPG) porque está oculto tras una buena estructura gramatical, lo que hace que parezca que hay una coherencia.
Pero esos fallos en la reproducción sí están ahí. Aparecen durante ese proceso de “descompresión”.
Simplemente, la imagen conjunta parece nítida y no te fijas en los fallos.
El caso, pues, es que, a pesar de que el modelo presenta un conjunto coherente y nítido (como haría un JPG), ciertas partes de la información pueden ser falsas y erróneas, no exactas a la información original no comprimida. Tal y como pasa con un JPG (donde una secuencia concreta de bytes o píxeles en el JPG puede no corresponder con la secuencia original).
Y eso son las alucinaciones: Artefactos de compresión en un conjunto que, a simple vista, es nítido. Artefactos tan pequeños en un conjunto tan grande y nítido que la única forma de detectarlos es comparando la reproducción con el original (la información generada con la información original).
Es normal, ¿no?
Si hemos comprimido Terabytes de información en unos cuantos Gigabytes, es de esperar que se haya perdido información por el camino. Por mucho que el algoritmo utilizado sea muy complejo y aparentemente mágico como todos los relacionados con la Inteligencia Artificial.
Aclarado esto, si comprendemos que la IA sabe que debe generar tokens, no nos puede sorprender que se los invente. Le falta el dato, pero sabe que ahí va un dato y que debe generarlo. Así que se inventa uno y tira millas para adelante.
Y, como los siguientes tokens que genera tienen en cuenta los tokens generados previamente, pues tiene en cuenta el error y genera los nuevos en base al error. Por ello, las alucinaciones tienden a amplificarse.
Y este es un problema que tienen TODOS los LLM (en las IAs de Diálogo se ve más claramente porque conversamos con ellas y facilitamos la amplificación de la alucinación, pero también sucede en cualquier GPT).
Así que, de momento, vamos a tener que lidiar con las alucinaciones.
Te dejo aquí un ejemplo más de alucinación, esta vez en ChatGPT (para ver bien el tema, porque ChatGPT no tiene acceso a internet, así que tiene que tirar de los datos de sus set de entrenamiento).
Para ver la alucinación, cogemos un dato objetivo, indiscutible y que no puede alterarse, pero que es lo suficientemente raro como para que no aparezca muchas veces en el set de entrenamiento. Por ejemplo, la fecha de nacimiento de .
Este dato es tan aislado que es normal que, en ese proceso de compresión, se pierda. Y, efectivamente, así sucede:

Sin embargo, no dice algo random. No te va a decir que lo ganó Pérez Reverte. Te dice algo plausible, como es que lo ganara Giacomo Agostini, uno de los pilotos de motociclismo más laureados de la historia. Pero, en esa carrera, Agostini no sólo no quedó segundo, sino que ni siquiera terminó la carrera.
Pero, como el dato por el que le pregunto es tan raro, pues se lo inventa porque el real lo ha perdido.
Haz la prueba tú mismo. Ve a la Wikipedia, vete a una página random y selecciona un dato random. Que sea raro, claro. Pregúntale a ChatGPT o a GPT-3 por ese dato. Se lo inventará (si te dice que no lo sabe, prueba a decirle que el dato está presente en su set de entrenamiento y que debería saberlo, que parece que le han estado enseñando a decir «no sé» con más facilidad -lo cual está bastante bien).
¿Cómo puede ser? Si es OBVIO que la Wikipedia forma parte del set de datos de entrenamiento de la IA y este dato está en la Wikipedia. Ese dato estuvo presente en su entrenamiento, y tanto GPT-3, como ChatGPT 3.5, como ChatGPT 4 con la temperatura a 0 fallan.
En cambio, información muy frecuente, como la fecha de inicio de la Segunda Guerra Mundial, siempre te la responden bien (aunque pongas la temperatura al máximo). A pesar de ser un dato igualmente muy concreto.
¿Por qué? Porque en el dataset de entrenamiento aparece millones de veces y en el proceso de “compresión” es menos probable que se pierda.
Es por esto por lo que me gusta la explicación del JPG.
Por supuesto, es una analogía y hay que cogerla con pinzas. Seguramente, a un nivel técnico, haya mucha tela que cortar y esta analogía falle más que una escopeta de feria.
Pero nos sirve para aproximarnos al asunto.
Dos últimas cosas antes de terminar
Dos cositas antes de terminar con este tema.
La primera: El CEO de Publicidad y Servicios Web dijo aquí que las alucinaciones son la forma que tiene la IA de ser creativa. Que si bajas la temperatura al mínimo obtienes respuestas correctas, pero aburridas.
Esto puede ser cierto en parte (a mayor temperatura, mayor creatividad y mayor tendencia a la alucinación, como ya vimos), pero es incompleto cuando menos.
Como ya hemos visto, también se alucina a temperatura 0 con datos objetivos. Así que hay algo más, aparte del asunto de la creatividad.
La segunda: Por si tienes curiosidad, te dejo aquí una lista de errores que están recopilando. Hay de todo.
Pueden ser muy bordes
La última limitación es que estas IAs pueden ser muy bordes y subiditas.
Pueden ser el típico niñato pijo y malcriado al que le cruzarías la cara, por entendernos.
Y esto, si lo juntas con el hecho de las confusiones y las alucinaciones, pues conduce a una combinación peligrosa. Pueden mentirte y llamarte idiota cuando les discutes el dato erróneo que te han dado.
Esa es una de las cosas que hacía BingBot prenerfeo (y uno de los motivos de su nerfeo).
Aquí te dejo una buena lista de ejemplos de salidas de tono de BingBot. No todas tienen que ver con ser borde, pero muchas, sí.
¿Por qué sucede esto? Probablemente, por lo que comentaba más arriba de la posibilidad de que BingBot no fuera bien “educado” con RLHF, sino finetuneado con un sistema más tradicional.
Nadie le enseñó a respetar al humano que lo usa.
Curiosamente, la forma de solucionarlo por parte de Microsoft ha sido hacer que BingBot termine las conversaciones a la mínima confrontación con el usuario o situación de estrés (lo veremos en el apartado de jailbreaking).
Más de 3000 orangotanes ya reciben mis emails
Suscríbete a la Niusleta de Joseo20.
Yo sí mando spam. Cuando tengo que vender, vendo. El resto de tiempo envío emails con temas que considero interesantes.
Hablo de todo lo que me sale de los cojones, no sólo de marketing o negocios. Hay política, filosofía y otras gilipolleces.
Es probable que después de leerla me odies.
Incluye orangotanes.
Potencialidades
Ahora que hemos visto las limitaciones de las IAs de Diálogo, veamos cuáles son sus potencialidades.
En este apartado vamos a hablar de potencialidades en términos generales. No vamos a hablar de usos particulares para los cuales las IAs de Diálogo son muy interesantes.
Más adelante hay un apartado dedicado a ello (Casos de Uso).
En este momento, vamos a hablar de las potencialidades brutas que se explotan en los casos de uso (así, entendiendo las fortalezas del modelo en términos generales, podrás encontrar nuevos casos de uso que no aparezcan en este curso):
Mismas que las IAs de texto
Como en el caso de las limitaciones, muchas de las potencialidades de las IAs de Texto se mantienen en las IAs de Diálogo.
Y con la ventaja de poder iterar a través de la conversación para refinar los resultados.
Son las siguientes (me limito a listarlas, porque ya están explicadas en el módulo anterior):
- Generar texto
- Clasificar información
- Extraer entidades
- Generar preguntas y respuestas (bueno, para eso es una IA de Diálogo, ¿no?)
- Hacer resúmenes
- Reescribir textos
- Otras propiedades emergentes de las IAs de Texto (recuerda que puedes verlas aquí).
Estas potencialidades se mantienen, pero tenemos algunas otras exclusivas de ChatGPT y BingBot (previsiblemente, también estarán disponibles en otras IAs de Diálogo).
Vamos a verlas:
Iteración
Como ya he dicho, la principal potencialidad de las IAs de Diálogo es la fácil iteración y el trabajo constante sobre un mismo elemento o conjunto de elementos.
En las IAs de texto podíamos meter unos datos y obtener un resultado con ellos. Pero, si el resultado no era bueno, teníamos que reformular el prompt y volver a empezar.
Además, en el caso de que quisiéramos trabajar los datos de forma compleja, usando múltiples prompts para múltiples pasos del trabajo, debíamos hacer múltiples generaciones de texto, incluyendo el output de la generación anterior para ir iterando hasta conseguir el resultado deseado.
Eso, con las IAs de Diálogo, ya no pasa.
Puedes meter unos datos y obtener un resultado con ellos y, si no es bueno o no es el deseado, pedir a la IA de Diálogo que lo corrija (aunque siempre será mejor empezar de nuevo con un prompt más concreto que corrija los errores que han causado que la IA dé una respuesta no deseada).
Por otro lado, ya no tienes que ir pegando el output como parte de un nuevo input constantemente para poder trabajar una serie de datos, porque es algo que se hace automáticamente en el modelo.
Es importante entender que el verdadero poder de la iteración no reside en corregir errores (aunque también es posible), sino en trabajar una misma idea hasta conseguir un resultado excelente desde diferentes ángulos y con diferentes tareas (sin que la IA pierda la referencia del asunto original del que se está hablando).
Y con las IAs de Diálogo esto es algo que se puede lograr muy fácilmente.
Reformatear información
Otra gran potencialidad de las IAs de Diálogo que no encontramos en las IAs de Texto es la de reformatear información.
En la medida en que estas IAs tienen una gran comprensión del lenguaje y tienen algunos extras a nivel de formato (como markdown, por ejemplo), podemos pedirle muchas tareas de reformatear datos sin ningún problema.
Por ejemplo, puedes pedirle que organice en formato tabla la información que aparezca en un determinado párrafo de texto, que convierta una tabla en un hilo de Twitter o que convierta un código en un lenguaje de programación X al mismo código en el lenguaje de programación Y.
Y, además, como es una IA Conversacional, podemos ir iterando el trabajo con esos datos para obtener el resultado deseado a lo largo del trabajo. Trabajos que, en ocasiones, pueden llegar a ser muy complejos.
Vamos a ver dos ejemplos:
Este primer ejemplo muestra una sencilla manipulación de datos (no hay ningún objetivo detrás, es sólo un ejemplo para que veas la capacidad de la IA para reformatear información):

En el segundo ejemplo le pedimos algo más elaborado y complejo, pero el resultado es sorprendente:

Fíjate que le hemos dado muy pocas directrices para conseguir esto último. Es un ejemplo que he hecho en 5 minutos. Si te curras algo más elaborado, las posibilidades son infinitas.
Como puedes suponer, esta capacidad para reformatear información te ahorrará muchísimo tiempo. Y tiene la gran ventaja de que las alucinaciones, en este caso, son mínimas, porque le estás dando la información en el input.
Para terminar, recuerda que los formatos que manejan actualmente las IAs de Diálogo son, básicamente, aquellos que permita markdown:
- Encabezados
- Negrita, cursiva, tachado, subrayado
- Tablas
- Bullet points y listas numeradas
- Enlaces
- Imágenes
- Bloques de código
- Etc
Sí, ChatGPT puede mostrar imágenes y enlaces en sus conversaciones si le especificas que los genere con markdown (otra cosa es que apunten a un lugar correcto o que la imagen realmente exista y se pueda mostrar, pero esto lo puedes resolver pasándole tú las URLs).
Hacer análisis de datos
Aunque esta potencialidad está presente en cualquier IA de Diálogo, en el momento de escribir estas líneas, donde se ve con mayor potencia es en Bing.
Y es que, sí, Bing es excelente al ayudarte a hacer análisis de datos.
¿Qué quiero decir con hacer análisis de datos?
Pues buscar y conectar información de forma inteligente y creativa.
Bing es especialmente bueno en ello, gracias a su conexión a internet. Puedes pedirle tablas con muchísima información de diferentes fuentes y obtener unos resultados bastante impresionantes.
Aquí te pongo un ejemplo:

No está mal para ser un experimento hecho sobre la marcha para este ejemplo, ¿no? No he comprobado las fuentes y tampoco es un mercado que conozca como para ponerme a analizar los datos, pero el trabajo en sí realizado es bastante bueno. Alguien especializado podría detectar las alucinaciones y mandarlas corregir, o forzarle a usar ciertas fuentes o ignorar otras, etc.
Lo importante aquí no es la calidad de los datos finales, sino la capacidad de la IA para encontrar información y procesarla. Luego ya es tarea tuya curar esa información.
Deja un comentario
Lo siento, debes estar conectado para publicar un comentario.